The launch/capture event of a positive edge-triggered flip-flop happens on every positive edge of the clock, whereas that of a negative edge-triggered flip-flop occurs on the negative edge of the flip-flop. In this post, we will discuss the default setup/hold checks different cases - same clock, 1:n clock ratio clock and n:1 ratio clock. And this should cover all the possible cases of setup/hold checks.
Case 1: Both flip-flops getting same clock
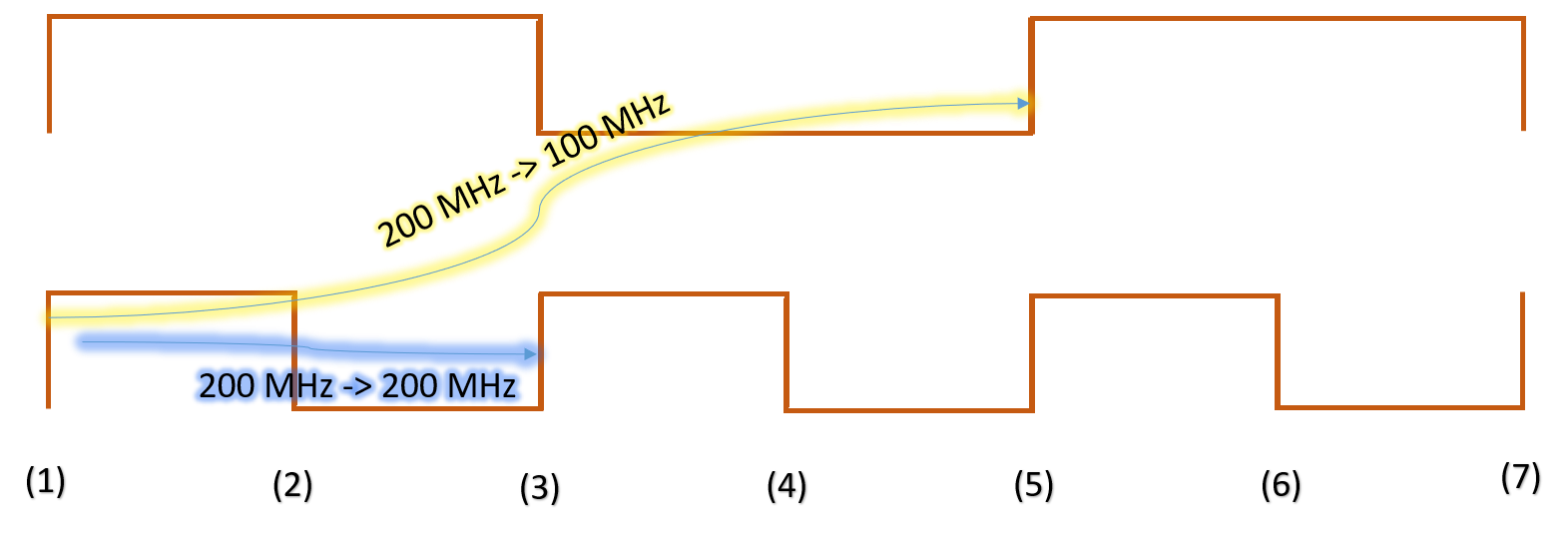
Figure 1: Pos-flop to neg-flop default setup/hold checks when clocks are equal in frequency
Figure 1 shows a timing path from a positive edge-triggered flip-flop to a negative edge-triggered flip-flop. Let us say the data is launched at instant of time "T", which is a positive edge. Then, the next negative edge following time "T" serves as the edge which captures this data; thus forming the default setup check. And the very previous negative edge serves as the hold check. This is shown in the first part of figure 1. Thus, in this case, both setup and hold checks are half cycle.
Setup and hold slack equations
Setup slack = Period(clk)/2 + Tskew - Tclk_q - Tcomb - Tsetup
Hold slack = Period(clk)/2 + Tclk_q + Tcomb - Tskew - Thold
Case 2: Flip-flops getting clocks with frequency ratio N:1 and positive edge of launch clock coincides with negative edge of capture clock
One of the cases where this happens is when clock is divided by an even number. Another is when odd division is followed by inversion. The resulting waveform will be as shown in figure 2. In this case, each positive edge of launch flip-flop is capable of launching a fresh data, but will be overwritten by next data. Only the one which is launched on the positive edge closest to the negative edge of capture clock will get captured at the endpoint. Similarly, the data which is launched at the edge coinciding negative edge of capture clock must not overwrite the data captured at the same edge. The setup and hold checks, thus formed, are as shown in figure 2 below. The setup check is full cycle of launch clock, whereas hold check is a zero cycle check.
Figure 2: Default setup/hold checks for case 2
Setup and hold slack equations
Setup slack = period(launch_clock) + Tskew - Tclk_q - Tcomb - Tsetup
Hold slack = Tclk_q + Tcomb - Tskew - Thold
Case 3: Flip-flops gettings clocks with frequency ration N:1 and positive edge of launch clock coincides with positive edge of capture clock
One of the cases where this happens is when capture of the data happens on an odd divided clock. The resulting setup and hold checks are as shown in figure 3. Both setup and hold checks are half cycle of faster launch clock.
Figure 3: Default setup/hold checks for case 3
Setup and hold slack equations
Setup slack = period(launch_clock)/2 + Tskew - Tclk_q - Tcomb - Tsetup
Hold slack = period(launch_clock)/2 + Tclk_q + Tcomb - Tskew - Thold
Case 4: Flip-flops getting clocks with frequency 1:N and positive edge of launch clock coincides with negative edge of capture clock
One of the cases is when division is performed after inversion of the master clock and data is launched on the divided clock. Figure 4 shows the default setup/hold checks for this case. In this case, setup check is equal to full cycle of faster clock and hold check is a zero cycle check.
Figure 4: Default setup/hold checks for case 4
Setup and hold slack equations
Setup slack = period(capture_clock) + Tskew - Tclk_q - Tcomb - Tsetup
Hold slack = Tclk_q + Tcomb - Tskew - Thold
Case 5: Flip-flops getting clocks with frequency 1:N and positve edge of launch clock coincides with positive edge of capture clock
This is a case of even division, or inversion, followed by odd division, followed by inversion. The setup and hold checks, both are equal to half cycle of faster clock.
Setup and hold slack equations
Setup slack = period(capture_clock)/2 + Tskew - Tclk_q - Tcomb - Tsetup
Hold slack = period(capture_clock)/2 + Tclk_q + Tcomb - Tskew - Thold
Can you think of any other scenario of setup/hold checks for this case? Please feel free to share your views.